scrapy框架基于selenium,多页面爬取简书文章内容、作者,ajax技术传递的数据等
保存到MongoDB中


class JieshuxSpider(CrawlSpider): name = 'jieshux' allowed_domains = ['jianshu.com'] start_urls = ['https://www.jianshu.com/'] rules = ( Rule(LinkExtractor(allow=r'.*/p/[a-z0-9]{12}.*'), callback='parse_item', follow=True), ) def parse_item(self, response): title = response.xpath('//h1[@class="title"]/text()').get() content = response.xpath('//div[@class="show-content-free"]').get() author = response.xpath('//div[@class="info"]/span[@class="name"]/a/text()').get() publish_time = response.xpath('//div[@class="info"]/div/span[@class="publish-time"]/text()').get()\ .replace('*', '') word_count = response.xpath('//div[@class="info"]/div/span[@class="wordage"]/text()').get().split(' ')[-1] read_count = response.xpath('//div[@class="info"]/div/span[@class="views-count"]/text()').get().split(' ')[-1] comment_count = response.xpath('//div[@class="info"]/div/span[@class="comments-count"]/text()').get().split(' ')[-1] like_count = response.xpath('//div[@class="info"]/div/span[@class="likes-count"]/text()').get().split(' ')[-1] subprocess = response.xpath('//div[@class="include-collection"]').get() art_id = response.url.split('?')[0].split('/p/')[-1] items = JieshuItem(title=title, content=content, art_id=art_id, author=author, publish_time=publish_time, url=response.url, word_count=word_count, read_count=read_count, comment_count=comment_count, like_count=like_count, subprocess=subprocess) yield items
class JieshuSeleniumDownloaderMiddleware(object): def __init__(self): self.chromedriver = webdriver.Chrome(executable_path=CHROMEDRIVER_PATH) def process_request(self, request, spider): self.chromedriver.get(request.url) time.sleep(1) while 1: try: more = self.chromedriver.find_element_by_class_name('show_more') more.click() time.sleep(0.3) except: break source = self.chromedriver.page_source.encode('utf-8') response = HtmlResponse(url=self.chromedriver.current_url, body=source, request=request) return response
class JieshuPipeline(object): def __init__(self): self.db = pymongo.MongoClient('127.0.0.1:27017') def open_spider(self, spider): self.database = self.db['jianshu'] self.table = self.database['jianshu'] def process_item(self, item, spider): self.table.insert_one(dict(item)) return item def close_spider(self, spider): self.db.close()
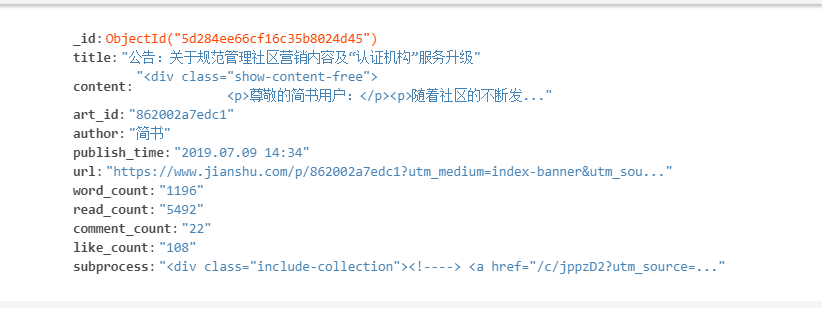
class JieshuItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() title = scrapy.Field() content = scrapy.Field() art_id = scrapy.Field() author = scrapy.Field() publish_time = scrapy.Field() url = scrapy.Field() word_count = scrapy.Field() read_count = scrapy.Field() like_count = scrapy.Field() comment_count = scrapy.Field() subprocess = scrapy.Field()
利用下载器中间件方法process_request中返回response对象,跳过原本下载器对网页的下载。
利用selenium.Chrome()实现对ajax传递的信息的获取。